20 / 12 / 17
「重学 OC」内存管理01 - 详解isa
我们在研究对象的本质的时候提到过isa,当时说的是isa是个指针,存储的是个类对象或者元类对象的地址,实例对象的isa指向类对象,类对象的isa指向元类对象。确实,在arm64架构(真机环境)前,isa单纯的就是一个指针,里面存储着类对象或者元类对象地址,但是arm64架构后,系统对isa指针进行了优化,我们在源码中可以探其结构:

可以看到,isa是个isa_t类型的数据,我们在点进去看一下isa_t是什么数据:

isa_t是个union结构,里面包含了一个结构体,结构体里面是个宏ISA_BITFIELD,我们看看这个宏是什么?

也就是这个结构体里面包含很多东西,但是究竟是什么东西要根据系统来确定。
那么在arm64架构下,isa指针的真实结构是:

在我们具体分析isa内部各个参数分别代表什么之前,我们需要弄清楚这个union是什么呢?我们看着这个union和结构体的结构很像,这两者的区别如下:
union:共用体,顾名思义,就是多个成员共用一块内存。在编译时会选取成员中长度最长的来声明。 共用体内存=MAX(各变量) struct:结构体,每个成员都是独立的一块内存。 结构的内存=sizeof(各变量之和)+内存对齐。
也就是说,union共用体内所有的变量,都用同一块内存,而struct结构体内的变量是各个变量有各个变量自己的内存,举例说明:
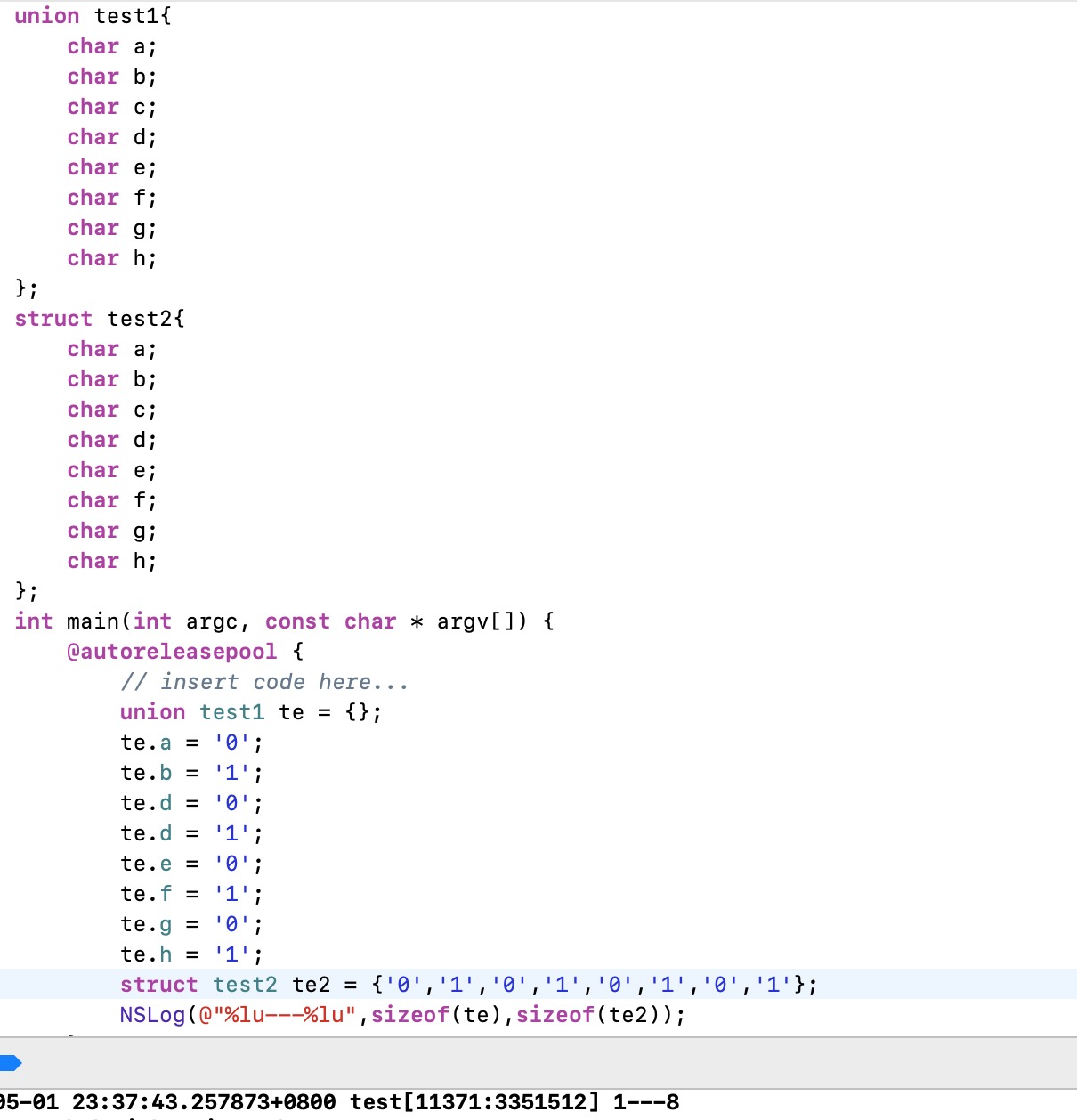
我们分别定义了一个共用体test1和一个结构体test2,里面都各自有八个char变量,打印出来各自占用内存我们发现共用体只占用了1个内存,而结构体占用了8个内存,
其实结构体占用8个内存很好理解,8个char变量,每个char占用一个,所以是8;而union共用体为什么只占用一个呢?这是因为他们共享同一个内存存储东西,他们的内存结构是这样的:
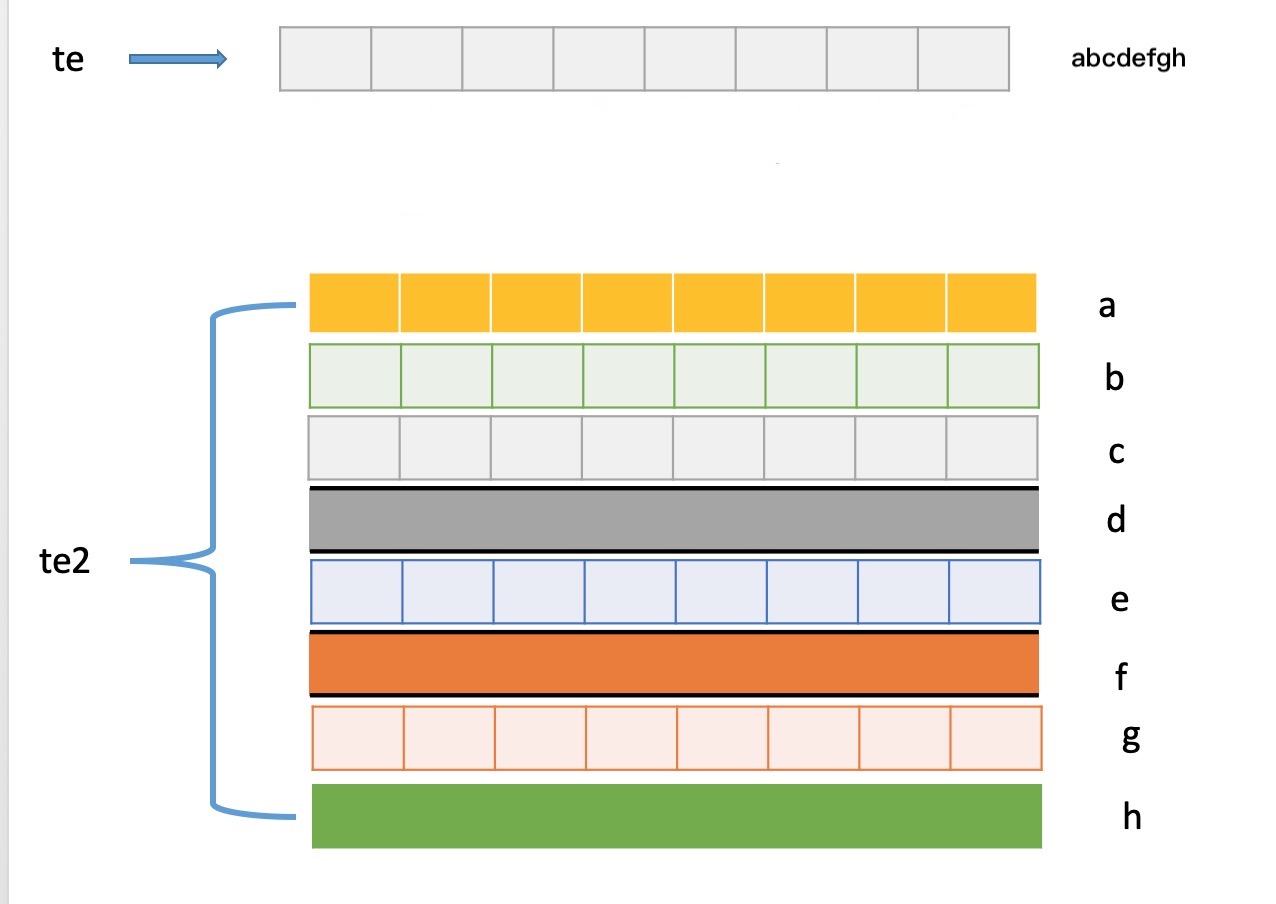
我们看到te就一个内存空间,也就是所有的公用体成员公用一个空间,并且同一时间只能存储其中一个成员变量的值,这一点我们可以打断点或打印进行确认:
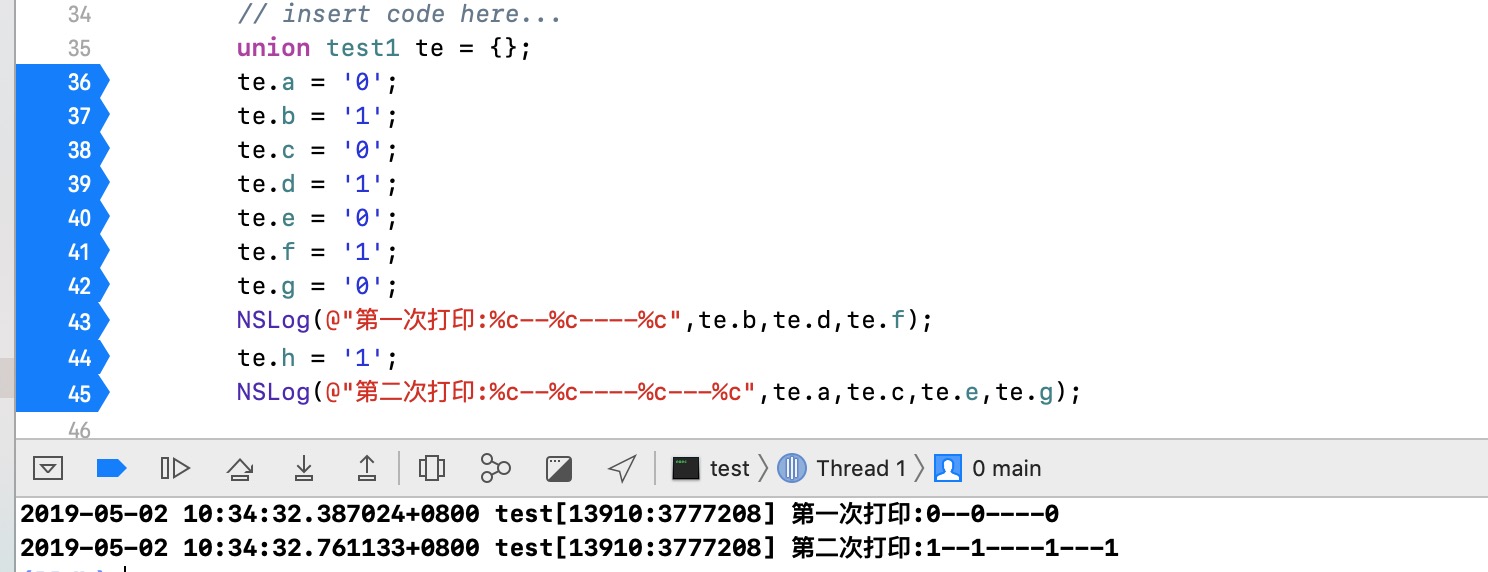
我们发现,第一次打印的时候,bdf这些值都是1的打印出来都是0,这是因为当te.g = '0',执行完后,这个内存存储的是g的值0,所以访问的时候打印结果都是0。第二次打印同理,te.h执行完内存中存储的是1,再访问这块内存那么得到的结果都会是1。
所以我们从这也可以看出,union共用体就是系统分配一个内存供里面的成员共同使用,某一时间只能存储其中某一个变量的值,这样做相比结构体而言可以很大程度的节省内存空间。
既然我们已经知道isa_t使用共用体的原因是为了最大限度节省内存空间,那么各个成员后面的数字代表什么呢?这就涉及到了位域。
我们看到union共用体为了节省空间是不断的进行值覆盖操作,也就是新值覆盖旧值,结合位域的话可以更大限度的节约内存空间还不用覆盖旧值。我们都知道一个字节是8个bit位,所以位域的作用就是将字节这个内存单位缩小为bit位来存储东西。我们把上面这个union共用体加上位域:

上面这段代码的意思就是,abcdefgh这八个char变量不再是不停地覆盖旧值操作了,而是将一个字节分成8个bit位,每个变量一个bit位,按照顺序从右到左一次排列。
我们都知道char变量占用一个字节,一个字节有8个bit位,也就是char变量有8位,那么te和te2的内存结构如下所示:
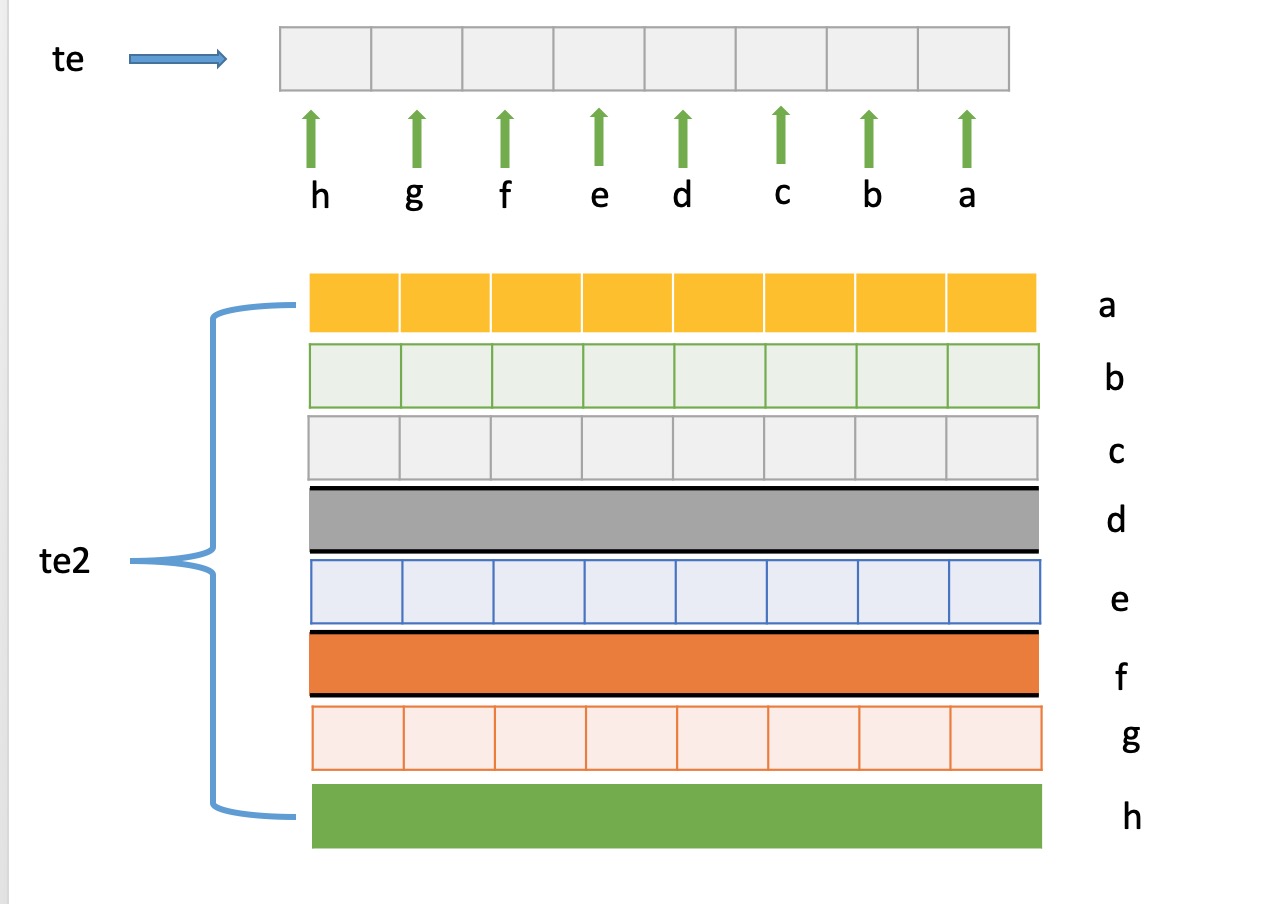
这个结构我们也可以通过打印来验证:te占用一个字节位置,内存地址对应的值是0xaa,转换成二进制正好是10101010,也就是a~h存储的值。
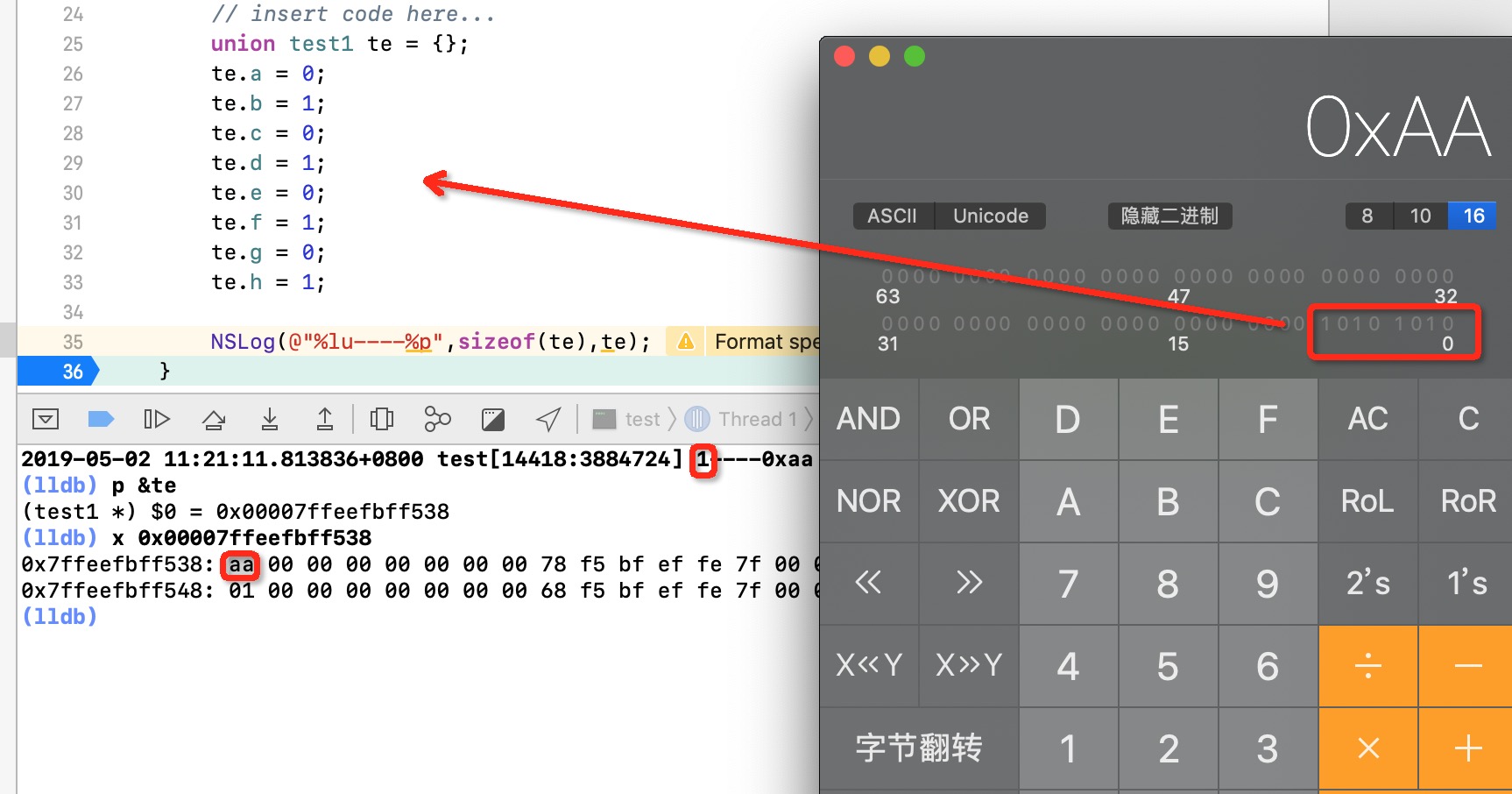
我们可以看到,现在是将一个字节中的8个bit位分别让给8个char变量存储数据,所以这些char变量存储的数据不是0就是1,可以看出来这种方式非常省内存空间,将一个字节分成8个bit位存储东西,物尽其用。所以我们根据isa_t结构体中的所占用bit位加起来=64可以得知isa指针占用8个字节空间。
虽然位域极大限度的节省了内存空间,但是现在面临着一个问题,那就是如何给这些变量赋值或者取值呢?普通结构体中因为每个变量都有自己的内存地址,所以直接根据地址读取值即可, 但是union共用体中是大家共用同一个内存地址,只是分布在不同的bit位上,所以是没有办法通过内存地址读取值的,那么这就用到了位运算符,我们需要知道以下几个概念:
&:按位与,同真为真,其余为假
|:按位或,有真则真,全假则假
<<:左移,表示左移动一位 (默认是00000001 那么1<<1 则变成了00000010 1<<2就是00000100)
~:按位取反
掩码 : 一般把用来进行按位与(&)运算来取出相应的值的值称之为掩码(Mask)。如 #define TallMask 0b00000100 :TallMask就是用来取出右边第三个bit位数据的掩码。
那么我们来看下这些运算符是怎么可以做到取值赋值的呢?比如说我们上面的te共用体内有8个char,要是我们想出去char b的值怎么取呢?这就用到了&:

按位与上1<<1 就可以取出b位的值了,b是1那么结果就是1,b是0那么结果就是0;
同理,当我们为f设置值的时候,也是类似的操作,就是在改变f的值的同时不影响其他值,这里我们要看赋的值是0还是1,不同值操作不同:

所以,这就是共同体中取值赋值的操作流程,那么我们接下来回到isa指针这个结构体中,看一下它里面的各个成员以及怎么取赋值的:
/*nonpointer 0,代表普通的指针,存储着Class、Meta-Class对象的内存地址 1,代表优化过,使用位域存储更多的信息 */ uintptr_t nonpointer : 1; \ /*has_assoc:是否有设置过关联对象,如果没有,释放时会更快*/ uintptr_t has_assoc : 1; \ /*是否有C++的析构函数(.cxx_destruct),如果没有,释放时会更快*/ uintptr_t has_cxx_dtor : 1; \ /*存储着Class、Meta-Class对象的内存地址信息*/ uintptr_t shiftcls : 33; /*MACH_VM_MAX_ADDRESS 0x1000000000*/ \ /*用于在调试时分辨对象是否未完成初始化*/ uintptr_t magic : 6; \ /*是否有被弱引用指向过,如果没有,释放时会更快*/ uintptr_t weakly_referenced : 1; \ /*对象是否正在释放*/ uintptr_t deallocating : 1; \ /*里面存储的值是引用计数器减1*/ uintptr_t has_sidetable_rc : 1; \ /* 引用计数器是否过大无法存储在isa中 如果为1,那么引用计数会存储在一个叫SideTable的类的属性中 */ uintptr_t extra_rc : 19;
我们看到,isa指针确实做了很大的优化,同样是占用8个字节,优化后的共用体不仅存放这类对象或元类对象地址,还存放了很多额外属性,接下来我们对这个结构进行验证:需要注意的是因为是arm64架构 所以这个验证需要是ios项目且需要运行在真机上 这样才会得出准确的结果。
首先,我们来验证这个shiftcls是否就是类对象内存地址。
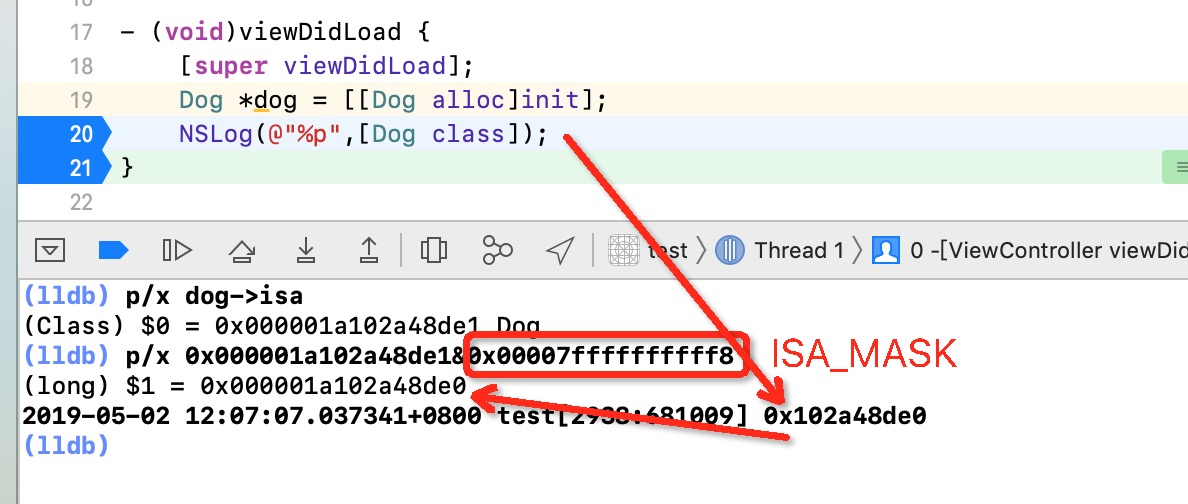
我们定义了一个dog对象,我们打印它的isa是0x000001a102a48de1
从上面的分析我们得知,要取出shiftcls的值需要isa的值&ISA_MASK(这个isa_mask在源码中有定义),得出$1 = 0x000001a102a48de0
而$1的地址值正是我们上面打印出来Dog类对象的地址值,所以这也验证了isa_t的结构。
我们还可以来看一下其他一些成员,比如说是否被弱指针指向过?我们先将上面没有被__weak指向过的数据保存一下,其中红色框中的就是这个属性,0表示没有被指向过
然后我们修改代码,添加弱指针指向dog:
__weak Dog *weaKDog = dog;
注意:只要设置过关联对象或者弱引用引用过对象,has_assoc或weakly_referenced的值就会变成1,不论之后是否将关联对象置为nil或断开弱引用。
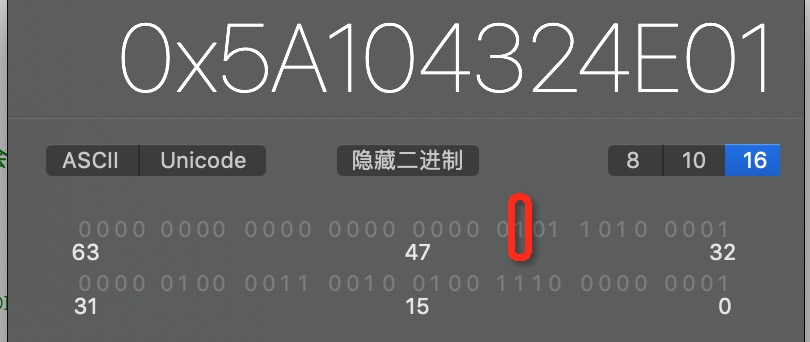
发现确实由0变成了1,所以可以验证isa_t的结构,这个实验要确保程序运行在真机才能出现这个结果。所以arm64后确实对isa指针做了优化处理,不在单纯的存放类对象或者元类对象的内存地址,而是除此之外存储了更多内容。
SideTable
struct SideTable {
spinlock_t slock; // 自旋锁
RefcountMap refcnts; // 引用计数表(散列表)
weak_table_t weak_table; // 弱引用表(散列表)
......
}
SideTable存储在SideTables()中,SideTables()本质也是一个散列表,可以通过对象指针来获取它对应的(引用计数表或者弱引用表)在哪一个SideTable中。在非嵌入式系统下,SideTables()中有 64 个SideTable。以下是SideTables()的定义:
static objc::ExplicitInit<StripedMap<SideTable>> SideTablesMap;
static StripedMap<SideTable>& SideTables() {
return SideTablesMap.get();
}
所以,查找对象的引用计数表需要经过两次哈希查找:
- 第一次根据当前对象的内存地址,经过哈希查找从SideTables()中取出它所在的SideTable;
- 第二次根据当前对象的内存地址,经过哈希查找从SideTable中的refcnts中取出它的引用计数表。
为什么不是一个SideTable,而是使用多个SideTable组成SideTables()结构?
如果只有一个SideTable,那我们在内存中分配的所有对象的引用计数或者弱引用都放在这个SideTable中,那我们对对象的引用计数进行操作时,为了多线程安全就要加锁,就存在效率问题。 系统为了解决这个问题,就引入 “分离锁” 技术方案,提高访问效率。把对象的引用计数表分拆多个部分,对每个部分分别加锁,那么当所属不同部分的对象进行引用操作的时候,在多线程下就可以并发操作。所以,使用多个SideTable组成SideTables()结构。